
Inverses
Something that is easy to miss in early calculus classes is that the inverse of a function is typically not a function. We go through this whole confusing notion first with the square root (because while it is true that if 

Typically though, inverse images will have more than one point. Indeed, for a map 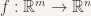

What I have in mind is that, if you have a function 

That last paragraph was confusing, so let me give an example right away. We will look at the function f which maps from the solid torus (donut) to the real numbers, so

The map of the torus that gives the radius of a point. The line in red is the range of the map. Notice it intersects with every shell exactly once.
that f(x) is the distance of x from the center of the solid torus. Hence 
This picture has a nice intuition: each surface will map down to one point (so our intuition earlier holds up- f maps a three dimensional object down onto one dimension, so the inverse images are all two dimensional), so we can easily look at this and see the domain, range and action of f on the domain. Notice also that to plot this in a traditional manner it would take either 4 dimensions as a graph, or 1 overloaded dimension as a parametric plot. This particular example *could* be displayed using a movie, though again we would be displaying fibers of the map.
The last image of this sort is where we instead map a torus (again, non-solid) to a circle. Notice that now the map is from a 2-D surface to a 1-D curve, so we expect (and see that) the fibers to be 1 dimensional.

The inverse images of the torus-radius map, as the radius goes from 0 to 1.

Inverse images of a projection-of-sorts of the torus onto a circle.

 would be the familiar calculus inner product on
would be the familiar calculus inner product on  .
. for vectors v,w; linearity,
for vectors v,w; linearity,  for scalars a,b and vectors v,w,z (note that by symmetry, I only need to require linearity for the first coordinate, and I automatically get it in the second); and positive definiteness, that is
for scalars a,b and vectors v,w,z (note that by symmetry, I only need to require linearity for the first coordinate, and I automatically get it in the second); and positive definiteness, that is  (or 0 if v is the zero vector).
(or 0 if v is the zero vector).
 . An important inner product is on the space of square integrable (real valued) functions, denoted
. An important inner product is on the space of square integrable (real valued) functions, denoted  . Then we can define an inner product between two functions (the vectors in this vector space) by
. Then we can define an inner product between two functions (the vectors in this vector space) by 

 , but since pi is not a rational number, the sequence will not converge in the rationals.
, but since pi is not a rational number, the sequence will not converge in the rationals. . The surprising fact (theorem!) is that given a continuous linear function f on H, there is a unique vector v so that
. The surprising fact (theorem!) is that given a continuous linear function f on H, there is a unique vector v so that  for all w in H. Put another way: not only does the inner product on H provide a supply of examples of continuous linear functionals, it provides all of them.
for all w in H. Put another way: not only does the inner product on H provide a supply of examples of continuous linear functionals, it provides all of them.
![F[u] = \int f(x)u(x)~dx](https://s0.wp.com/latex.php?latex=F%5Bu%5D+%3D+%5Cint+f%28x%29u%28x%29%7Edx&bg=f7f3ee&fg=333333&s=0&c=20201002) for some function f. It becomes a little less surprising when you realize that part of the trick in the theorem is requiring continuity, which is defined in terms of the inner product. But hey! Still pretty cool!
for some function f. It becomes a little less surprising when you realize that part of the trick in the theorem is requiring continuity, which is defined in terms of the inner product. But hey! Still pretty cool!

 (since a second order linear operator is just something that eats functions and gives back functions, in a linear manner):
(since a second order linear operator is just something that eats functions and gives back functions, in a linear manner):

 , for which
, for which  is 1 when j = k, and 0 otherwise, and
is 1 when j = k, and 0 otherwise, and  s and c are zero. Put more simply, the Laplacian is the sum of the pure second derivatives. Now we provide first an outline, and then a few details of a proof of existence of solutions.
s and c are zero. Put more simply, the Laplacian is the sum of the pure second derivatives. Now we provide first an outline, and then a few details of a proof of existence of solutions.![B[u,v] = \lambda(v)](https://s0.wp.com/latex.php?latex=B%5Bu%2Cv%5D+%3D+%5Clambda%28v%29&bg=f7f3ee&fg=333333&s=0&c=20201002) for any v, where
for any v, where  is a linear functional (eats functions, gives a number).
is a linear functional (eats functions, gives a number). .
.![B[u,v]:=\int\left(\sum_{j,k = 1}^na^{j,k}u_{x_j}v_{x_k}+\sum_{j = 1}^nb^ju_{x_j}v+cuv\right)dx,](https://s0.wp.com/latex.php?latex=B%5Bu%2Cv%5D%3A%3D%5Cint%5Cleft%28%5Csum_%7Bj%2Ck+%3D+1%7D%5Ena%5E%7Bj%2Ck%7Du_%7Bx_j%7Dv_%7Bx_k%7D%2B%5Csum_%7Bj+%3D+1%7D%5Enb%5Eju_%7Bx_j%7Dv%2Bcuv%5Cright%29dx%2C&bg=f7f3ee&fg=333333&s=0&c=20201002)

![B[u,v]=\int Lu\cdot v~dx](https://s0.wp.com/latex.php?latex=B%5Bu%2Cv%5D%3D%5Cint+Lu%5Ccdot+v%7Edx&bg=f7f3ee&fg=333333&s=0&c=20201002) . In this beautiful, integrable, differentiable world, if we could show that
. In this beautiful, integrable, differentiable world, if we could show that  for all functions v, then it would be reasonable to conclude that Lu = f.
for all functions v, then it would be reasonable to conclude that Lu = f. and a (continuous) linear functional
and a (continuous) linear functional  , there is a unique
, there is a unique 

![B[u,v]=\lambda(v)](https://s0.wp.com/latex.php?latex=B%5Bu%2Cv%5D%3D%5Clambda%28v%29&bg=f7f3ee&fg=333333&s=0&c=20201002) for each
for each  . There are some other non-trivial hypotheses on B, which may be translated into hypotheses on L, but let’s revel in success now.
. There are some other non-trivial hypotheses on B, which may be translated into hypotheses on L, but let’s revel in success now. , the m-times differentiable functions- are not Hilbert spaces. Certain Sobolev spaces are, though, and they provide precisely the integrability conditions we need to get precise conditions to guarantee solutions for large classes of PDE.
, the m-times differentiable functions- are not Hilbert spaces. Certain Sobolev spaces are, though, and they provide precisely the integrability conditions we need to get precise conditions to guarantee solutions for large classes of PDE.




 , where
, where  for each k. Then
for each k. Then  . There is an easy result (see, for example, Falconer’s “
. There is an easy result (see, for example, Falconer’s “ and
and  . Note that the Hausdorff measure might be 0 or infinite, but this number will still exist.
. Note that the Hausdorff measure might be 0 or infinite, but this number will still exist. .
.























